
GalTransl 简易教程
AI 汉化原理
游戏资源(文本、脚本、图片、视频等)被各种引擎以不同方式打包。静态汉化的核心思路是“偷梁换柱”:提取文本,翻译后再替换回去。
由于游戏脚本通常混合了显示文本和程序代码,AI 不能直接处理这种混合文件,否则极易将代码一并翻译,从而破坏游戏功能。因此,现代 AI 游戏汉化的基础工作原理是 “提取-翻译-回注” 策略,完整流程如下:
- 使用解包工具(如 GARbro)解包游戏文件。
- 精确提取脚本中需要翻译的文本,转换为中间格式(GalTransl 使用 JSON)。
- 配置 API,仅对提取出的文本进行 AI 翻译。
- 将译文精确回注到原始脚本的对应位置。
- 重新打包为游戏可读取的格式。
一、准备阶段
1. 翻译模型选择与 API 价格参考
由于 AI 模型迭代迅速且传统评测极易过时,如需追踪当前全球文学功底、翻译语感与润色能力最强的模型排位,请直接查阅盲测大模型权威榜单 👉 LMSYS 竞技场 (写作与语言类)。
配置翻译器时,翻译成本主要取决于你所选的模型梯队(即选择旗舰大模型,还是轻量/蒸馏模型)。选定心仪的模型后,只需获取对应的 API 即可开始配置。
💡 省钱提示:你可以借助 Grok 搜索低价的 API 中转站,例如那些整合了云服务商优惠额度,或提供主流开发者工具(如 kiro)网页端逆向接口的服务商。
🕵️ 科普:中转 API 凭什么这么便宜? 中转平台之所以能将价格打到官方的几十分之一,本质是把“薅大厂羊毛”做成了产业链。他们通过批量注册免费试用账号、滥用云厂商额度,或是将包月的个人订阅账号(如 ChatGPT Plus)逆向转化为高频 API 号池来极限分摊成本。一句话:用灰色的零本万利,换取极致的低价,但代价是偶尔会遇到掺水降智或接口不稳定的情况。
模型汉化费用估算参考 以下费用以 云雾API 的价格为例。
- 测算基准:一款文本量约 300 万(3M)Token 的中型游戏(按 3M 提取输入 + 3M 翻译输出计算)。
| 模型梯队 (代表模型) | 官方单价 (输入/输出 每 1M) | 中转单价 (约官价 5%) | 3M 游戏预估总花费 |
|---|---|---|---|
| 国际旗舰 (Claude Sonnet 4.6) | 21.0 / 105.0 元 | 1.5 / 7.5 元 | 约 27.0 元 |
| 国际轻量 (Claude Haiku 4.5) | 7.0 / 35.0 元 | 0.5 / 2.5 元 | 约 9.0 元 |
| 国产参考 (DeepSeek V4 Pro) | 3.0 / 6.0 元 | 1.5 / 3.0 元 | 约 13.5 元 |
二、实操流程
(以 KRKR / KiriKiri 引擎为例)
1. 解包游戏
使用 GARbro 等工具提取 .ks 等脚本文件。
2. 提取 JSON
- 打开 GalTransl 根目录。
- 运行
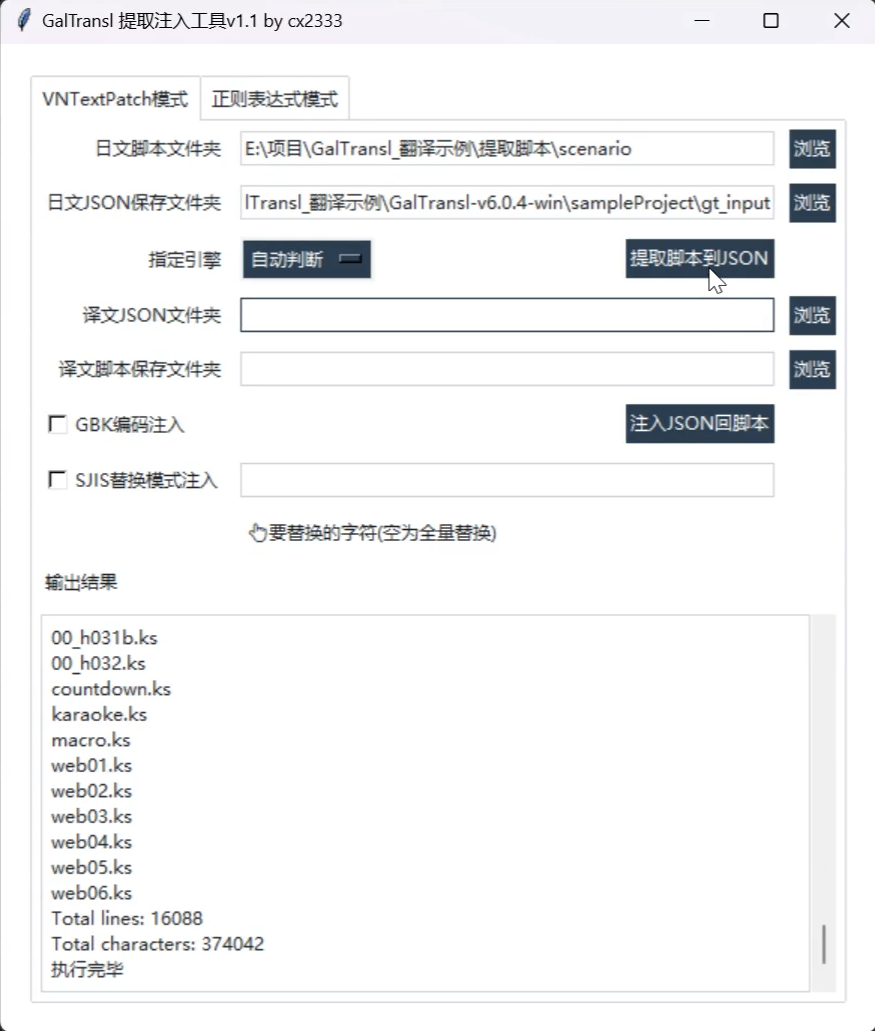
useful_tools\GalTransl_DumpInjector\GalTransl_DumpInjector.exe。 - 在工具界面中配置以下路径:
- 日文脚本文件夹:选择 GARbro 提取出的脚本文件夹。
- 日文JSON保存文件夹:推荐选择
SampleProject/gt_input。
- 点击 “提取脚本到JSON” 开始提取。
3. 设置翻译器
- 在根目录找到
SampleProject文件夹。 - 将
config.inc.yaml重命名为config.yaml。 - 使用文本编辑器打开并修改该配置文件。
⚠️ 重要警告:YAML 配置文件中,所有冒号
:后面必须保留一个半角空格!
backendSpecific:
OpenAI-Compatible: # (ForGal/gpt4/r1模板) OpenAI API 兼容接口通用
tokens:
- token: sk-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
endpoint: https://api.openai.com # 请求地址,使用转发或第三方 API 时修改
rewriteModelName: "gpt-4o" # 设置自定义的模型名称,用于调用 Claude/DeepSeek 等模型
filePlugin: file_galtransl_json # 支持更多格式:字幕用 file_subtitle_srt_lrc_vtt,小说用 file_epub_epub 或 file_plaintext_txt
workersPerProject: 16 # 同时翻译 n 个文件(单个文件需多线程时请开启 splitFile)4. 开始翻译
- 在项目目录中双击运行
run.bat。 - 将编辑好的
config.yaml拖入弹出的命令行窗口并按回车。 - 选择翻译模型后再次回车,开始翻译。 (注:翻译耗时取决于你设置的线程数和 API 的响应速度。)
5. 导出译文
翻译完成后:
- 再次打开
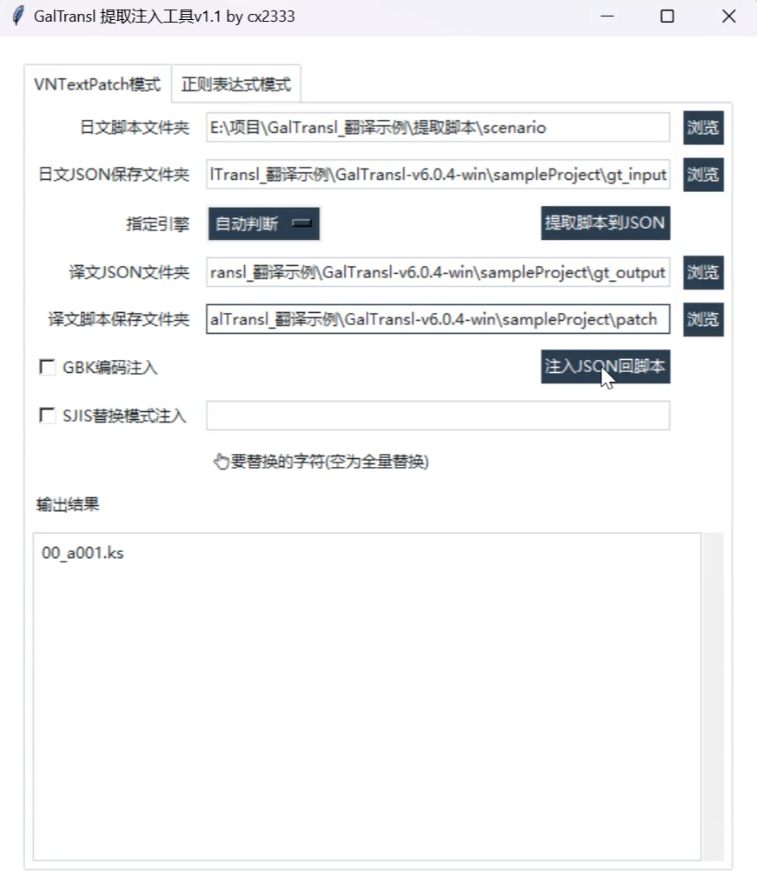
GalTransl_DumpInjector.exe。 - 设置以下路径:
- 日文脚本文件夹:原始脚本位置
- 日文JSON保存文件夹:
SampleProject/gt_input - 译文JSON保存文件夹:
SampleProject/gt_output - 译文脚本保存文件夹:选择你希望导出汉化脚本的位置
- 点击 “注入JSON回脚本” 完成导出。
6. 打包
- 普通 KRKR 引擎:使用
xp3_upk,直接将文件夹拖到工具上即可。 - 需保留目录结构的 KRKR 引擎:使用
arc_conv打包。 - 其他加密 KRKR 引擎:使用
KrkrExtract等专属工具处理。
三、其他引擎的游戏(进阶)
1. 引擎分析
使用 GARbro 获取引擎名称,随后在 GitHub 或搜索引擎上查找相关资料(建议借助 Grok 等具备联网能力的 AI 直接检索开源工具,效率更高)。
引擎分析决策树:
1. 游戏的文本是否加密?
├─ 否 → 直接提取并翻译
└─ 是 → 寻找文本解密和重加密工具
├─ 有工具 → 解密 → 翻译 → 重加密
└─ 没工具 → 考虑学习逆向,或转为动态汉化(如 Hook)
2. 该引擎是否有打包工具?
├─ 有 → 使用对应工具打包
└─ 没有 → 是否支持免封包读取?
├─ 支持 → 使用 MoleBox 等工具封包
└─ 不支持 → 考虑学习逆向,或转为动态汉化(如 Hook)2. 编码与乱码问题
当提取的脚本是 Shift-JIS 编码时,可能会遇到汉化后游戏内乱码的问题:
- 首选测试:尝试将文本转换为 Unicode 编码(UTF-16LE、UTF-8、GBK),测试游戏能否正常读取并显示。
- 备选方案:如果游戏强制要求 Shift-JIS 编码,有两种解决思路:
- 方案 A(硬核):通过逆向工程,修改游戏引擎使其支持 GBK 编码。
- 方案 B(巧妙):使用“汉字→日文替换表”(
hanzi2kanji_table.txt)结合特殊修改的字体来实现视觉上的中文显示。 (原理:这是示例文本(UTF-8) → 這是示例文本(Shift-JIS) → 这是示例文本(视觉呈现))
3. 打包示例
不同引擎需要不同的命令行打包方法,例如 Qlie 或 未加密 KRKR 引擎 可使用 arc_conv 工具:
arc_conv.exe --pack xp3 patch patch.xp3
arc_conv.exe --pack qlie data data8.pack对于其他陌生引擎,必须回到“引擎分析”步骤,寻找对应的专属打包工具。
四、翻译质量与优化
关于翻译缓存管理、自动化找错与修正,请务必阅读官方文档:
💡 核心建议: GPT 字典功能对最终的翻译质量影响极具决定性。强烈建议在开始批量翻译前,至少先在字典中配置好核心角色的人名和专属名词。
五、常见工具一览
| 工具名称 | 核心用途 | 特点说明 |
|---|---|---|
| GARbro | 拆包工具 | 功能强大,能识别绝大多数 Galgame 引擎(状态栏会显示引擎名称)。 |
| EmEditor | 编码处理 | 可批量指定文件的打开与保存编码,解决乱码痛点。 |
| Notepad— | 文本处理 | 支持强大的批处理和多文件正则替换。 |
| Python | 脚本工具 | 用于编写自定义的文本提取、数据转换和自动化脚本。 |
| GalTransl_DumpInjector | JSON 提取 | GalTransl 自带的图形化工具,开箱即用。 |
| Grok | 资料检索 | 适合快速定位 GitHub 上的解包/封包工具及相关技术文档。 |
六、免责声明
1.本教程仅作基础技术分享与思路探讨。涉及工具均为常规推荐,非标准操作恕不提供效果保证与技术答疑。 2.游戏文件修改具有固有的风险。操作前请务必做好文件备份,由此引发的数据丢失或程序故障需由您自行承担。 3.敬请尊重原作者知识产权。汉化成果仅限个人本地学习使用,谢绝任何形式的商业牟利与盗版传播。 4.文中提及的解包等逆向技术仅供学习参考。请在充分了解并自愿承担相关法律风险的前提下审慎使用。